当使用Kettle导入数据到数据表时,由于使用的是Oracle,所以自然而然想到使用增加序列对象去获取一个Id,但是经过测试这种方式非常慢。
以下对比2种不同方式的导入速度:
- 序列生成Id
- 分布式Id生成器
速度比较
序列
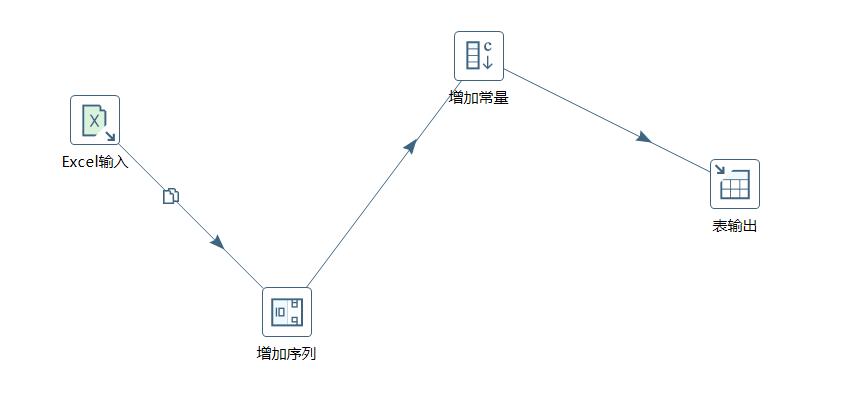
转换
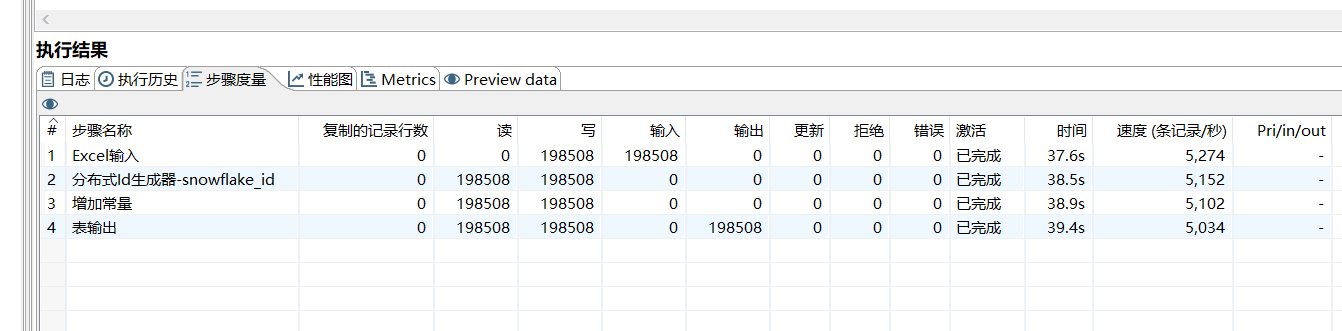
执行结果
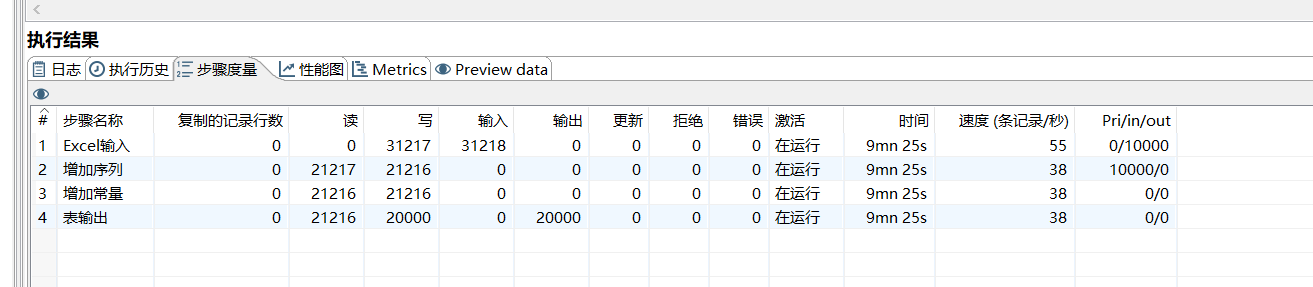
从图片可以看出来,使用序列生成Id的方式,导入数据是会非常慢。10分钟才导入2w多条记录。
分布式Id生成器
请参考:分布式Id生成器
使用
将以上 分布式Id生成器 文章的代码打包成jar包,放到kettle/lib文件夹下。假设包名、类名:top.ylonline.common.keygen.SnowflakeKeyGenerator.java
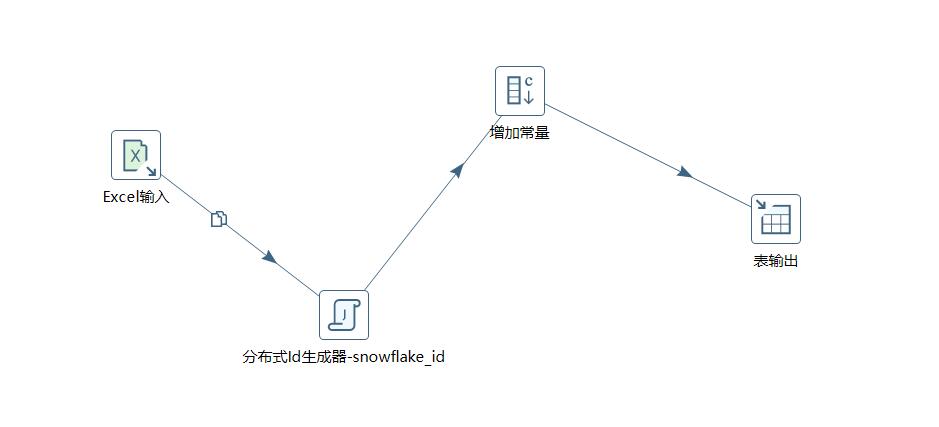
转换
Java代码对象
1 | import java.lang.*; |
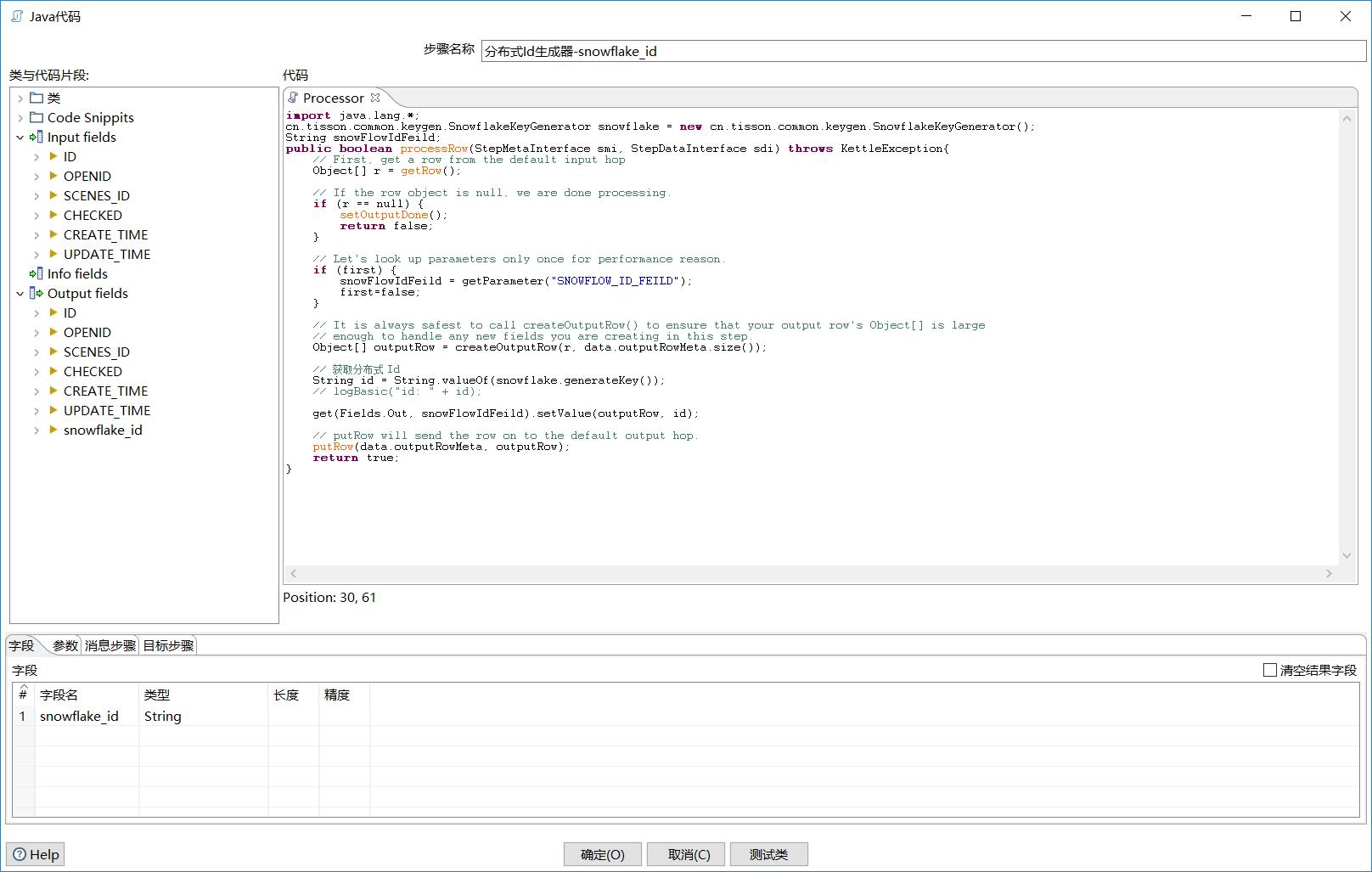
字段配置
字段名:snowflake_id
类型:String
参数配置
标签:SNOWFLOW_ID_FEILD
值:snowflake_id
执行结果